
Machine Learning (ML) is one of the fastest-growing fields in technology today. From recommendation systems on Netflix to self-driving cars and AI chatbots, Machine Learning is shaping the future of industries worldwide.
If you are planning to build a career in Machine Learning, this guide will help you understand the complete roadmap, career opportunities, hiring trends, salary expectations, and how to get a job in this field.
📌 What is Machine Learning?
Machine Learning is a branch of Artificial Intelligence (AI) that enables computers to learn from data and make decisions without being explicitly programmed. It focuses on building algorithms that improve automatically through experience.
ML is widely used in healthcare, finance, education, e-commerce, cybersecurity, and automation.
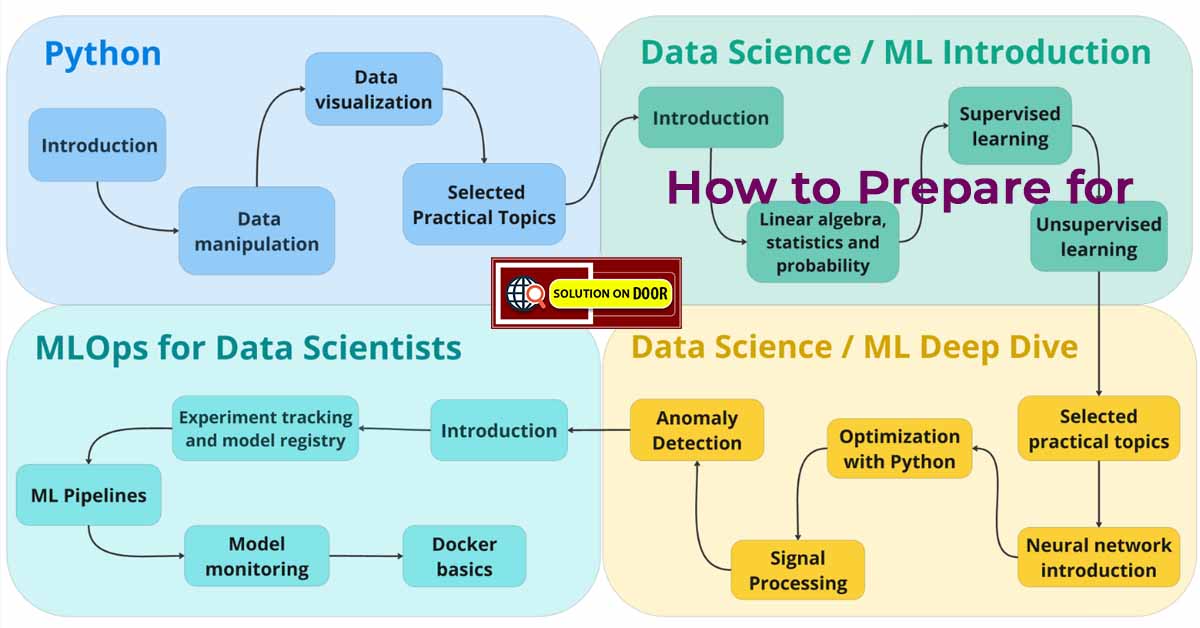
🛣️ 1. Roadmap for Machine Learning
To become a successful Machine Learning professional, follow this step-by-step roadmap.
✅ Step 1: Learn Mathematical Foundations
Strong fundamentals are essential for understanding ML algorithms.
You should focus on:
- Optimization Techniques
- Linear Algebra
- Probability & Statistics
- Calculus
✅ Step 2: Master Programming Skills
Python is the most popular language for Machine Learning.
Learn:
- Python Basics
- NumPy & Pandas
- Data Visualization (Matplotlib, Seaborn)
- SQL for Data Handling
✅ Step 3: Understand Core Machine Learning Concepts
Start with traditional ML techniques:
- Model Evaluation
- Supervised Learning
- Unsupervised Learning
- Regression & Classification
- Clustering
✅ Step 4: Learn Advanced Machine Learning
After mastering basics, move to advanced topics:
- Deep Learning
- Neural Networks
- Natural Language Processing (NLP)
- Computer Vision
- Reinforcement Learning
✅ Step 5: Work with ML Tools & Frameworks
Practical knowledge of tools is necessary:
- Scikit-Learn
- TensorFlow
- PyTorch
- Keras
- OpenCV
- SpaCy & NLTK
✅ Step 6: Build Real-World Projects
Projects prove your skills to employers.
Some project ideas:
- Face Recognition System
- Sales Prediction Model
- Chatbot Application
- Recommendation System
- Fraud Detection System
Publish your projects on GitHub and create demos.
🎯 2. Career Options in Machine Learning
Machine Learning offers multiple career paths.
Popular Job Roles:
- Machine Learning Engineer
- Data Scientist
- AI Engineer
- NLP Engineer
- Computer Vision Engineer
- Research Scientist
- MLOps Engineer
Each role requires a combination of programming, analytics, and domain knowledge.
📈 3. Current Hiring Trends in Machine Learning
In 2026, Machine Learning professionals are in high demand across industries.
Top Hiring Sectors:
- IT & Software Companies
- FinTech & Banking
- Healthcare & BioTech
- E-Commerce Platforms
- Automotive & Robotics
- EdTech Companies
- AI Startups
In-Demand Skills:
- Deep Learning
- NLP & Transformers
- Cloud ML
- MLOps
- AI Deployment
Candidates with hands-on experience and deployment knowledge are preferred.
💰 4. Salary Range in Machine Learning
Salary depends on experience, skills, and location.
📍 Salary in India
| Experience | Average Salary |
|---|---|
| Fresher | ₹4 – ₹8 LPA |
| 2–4 Years | ₹8 – ₹18 LPA |
| 5+ Years | ₹20 – ₹40 LPA |
🌍 Global Salary (USA/Europe)
| Experience | Salary (USD) |
|---|---|
| Entry Level | $90K – $120K |
| Mid Level | $120K – $160K |
| Senior Level | $160K+ |
🎓 5. How to Get a Job in Machine Learning?
Getting a job in ML requires strategy, practice, and consistency.
🔹 Step 1: Learn from Quality Resources
Use platforms like:
- Coursera
- Udemy
- edX
- YouTube
- Kaggle
Focus on practical learning.
🔹 Step 2: Build a Strong Portfolio
Your portfolio should include:
- 5–8 Quality Projects
- GitHub Profile
- Technical Blog (Optional)
- Live Project Demos
This helps recruiters evaluate your skills.
🔹 Step 3: Prepare for Interviews
Prepare for:
- ML Algorithms
- Python Coding
- Data Structures
- Statistics
- Case Studies
Practice on LeetCode, Kaggle, and HackerRank.
🔹 Step 4: Apply Smartly
Apply through:
- LinkedIn Jobs
- Naukri.com
- Indeed
- AngelList
- Company Career Pages
Customize your resume for each job role.
🔹 Step 5: Learn Deployment & MLOps
Modern companies expect candidates to know:
- Model Deployment
- Docker
- Cloud Platforms
- CI/CD Pipelines
- API Integration
This increases your hiring chances.
🌟 Tips for Success in Machine Learning
✔ Learn continuously
✔ Participate in Kaggle competitions
✔ Follow AI researchers
✔ Attend webinars and meetups
✔ Build industry-relevant projects
✔ Network on LinkedIn
📌 Conclusion
Machine Learning is a future-proof career with excellent growth opportunities. By following the right roadmap, building strong projects, and staying updated with industry trends, you can successfully enter this exciting field.





