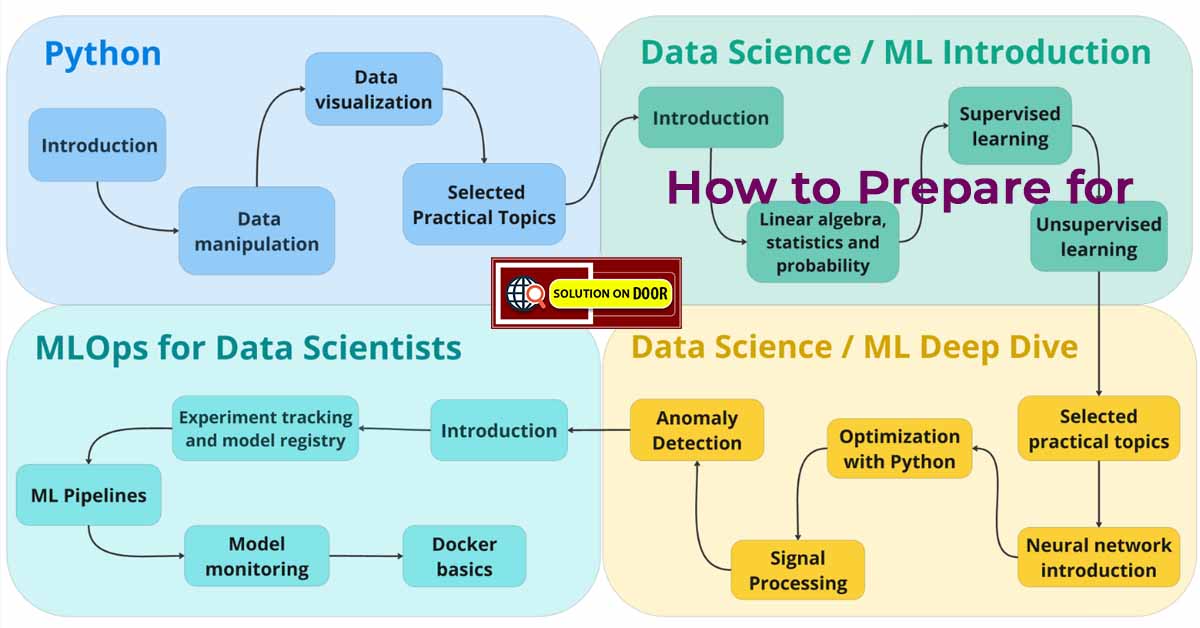
12 Feb 2026 rgwonder 0 Comments 🚀 Roadmap for Machine Learning: A Complete Career Guide (2026) Machine Learning (ML) is one of the fastest-growing fields in technology today. From recommendation systems on Netflix to self-driving cars and AI chatbots, Machine Learning is shaping the future of industries worldwide. If you are planning to build a career … Read the rest
26 Mar 2025 rgwonder 0 Comments How to Prepare for Object-Oriented Programming (OOP): A Roadmap for BTech Students Object-Oriented Programming (OOP) is a fundamental concept in software development. It helps in structuring programs efficiently and is widely used in real-world applications. For BTech students, mastering OOP is crucial as it forms the base for advanced programming and development… Read the rest
21 Mar 2025 rgwonder 0 Comments Hugging Face Champions Open-Source AI in White House Action Plan In a recent submission to the White House Office of Science and Technology Policy, Hugging Face has underscored the pivotal role of open-source AI systems and open science in advancing artificial intelligence. Their response to the White House AI Action … Read the rest
18 Mar 2025 rgwonder 0 Comments Naive Bayes Classifier vs Decision Tree in Machine Learning Machine Learning classification algorithms play a crucial role in predictive analytics, helping businesses and researchers make data-driven decisions. Two of the most widely used classification algorithms are Naive Bayes Classifier and Decision Tree. In this blog post, we will … Read the rest
16 Mar 2025 rgwonder 0 Comments Linear Regression in Machine Learning: A Complete Guide Introduction to Linear Regression Linear Regression is one of the fundamental algorithms in Machine Learning and Data Science. It is a supervised learning algorithm used for predicting continuous values based on input data. Linear regression is widely used in … Read the rest
15 Mar 2025 rgwonder 0 Comments Introduction to Machine Learning and Its History What is Machine Learning? Machine Learning (ML) is a subset of Artificial Intelligence (AI) that enables computers to learn from data and make decisions without being explicitly programmed. It uses algorithms to analyze patterns, improve performance over time, and make … Read the rest
12 Mar 2025 rgwonder 0 Comments Elon Musk’s X Platform Faces Massive Cyberattack Amid Global Outage Elon Musk’s X Platform Faces Massive Cyberattack Amid Global Outage X Platform | On March 10, 2025, Twitter, now rebranded as X, experienced a significant global outage attributed to a massive cyberattack. Elon Musk, the platform’s owner, confirmed the incident, … Read the rest